
Building sub-100ms autocompletion for JetBrains IDEs
We’re building a better autocomplete for JetBrains.
What makes a great autocomplete?
We believe these two aspects are necessary for a great autocomplete experience:
- High quality context: To be truly useful, the autocomplete should have enough context to make accurate suggestions.
- Fast response time: Developers don’t want to have to “pause” and then wait for suggestions.
Developers lose trust when autocomplete suggests code that doesn’t make sense, and missing context is the most common reason for this. Here’s how we built autocomplete that’s accurate without compromising on performance.
Building Autocomplete from Scratch
To achieve high-quality context, we focused on two key areas: sampling from code that developers actually change (using AST-diff sampling) and providing relevant context from recent commits.
Traditional FIM
We started with generating traditional fill-in-the-middle (FIM) autocomplete data. In FIM, the model is prompted to fill in the middle of a code snippet.
Here’s an example of how FIM is useful for autocomplete. The user’s cursor is shown as █.
def get_car_metadata(car: Car) -> str:
return f"█ {car.model} {car.year}"In this example, the code before the user’s cursor becomes the prefix, and the code after the user’s cursor becomes the suffix. The model is then trained to predict the middle.
Input:
<|prefix|>def get_car_metadata(car: Car) -> str:
return f"{<|suffix|>} {car.model} {car.year}"<|middle|>
Output:
car.makeThis generates a completion like this:
def get_car_metadata(car: Car) -> str:
return f"{car.make} {car.model} {car.year}"However, we will use a different format later to accommodate next-edit autocompletions.
Diff-based Syntax-Aware FIM
Standard FIM has a limitation: it treats code as arbitrary text rather than structured syntax, leading to suggestions that break at AST boundaries. Additionally, random sampling doesn’t focus on the code patterns that developers actually modify in practice. To address this, we used Diff-based Syntax-Aware FIM (SAFIM) to ensure all completions respect code structure.
We started by scraping ~80k FIM examples from 400 OSS permissively-licensed GitHub repositories created in the past 6 months. We do this to avoid data contamination and ensure that the data is not already in the base model’s pretraining data.
From this, we constructed Syntax-Aware FIM completions (SAFIM) so that all completions are all valid AST nodes, as opposed to random substrings that don’t respect AST boundaries.
Understanding Abstract Syntax Trees (AST)
The AST (Abstract Syntax Tree) is a hierarchical structure that represents code as meaningful chunks like “function declaration” or “method call” rather than arbitrary character sequences. For example, the following Java code would have the following AST:
public class Hello {
public static void main(String[] args) {
int x = 5 + 3;
System.out.println(x);
}
}
SAFIM only samples substrings corresponding to valid AST nodes of the code:

This approach targets the moments when developers face high-uncertainty decisions. For example, after typing foo.█ or foo(█), developers typically pause to consider which method or function to call, often searching their codebase for options. By focusing on these natural decision points, the system provides autocomplete suggestions when users actually need and expect them.
Diff-based Upsampling
Further, to upsample frequently edited node types, we diffed the AST trees of the file before and after the change from the commit, and only sampled from changed AST nodes.

We also provide context of the rest of the diffs of the commit (representing recent changes from the developer), and other files touched by the commit (representing the context of the developer’s currently opened files).
We found that the majority of Jetbrains users use Intellij (Java), Android Studio (Kotlin), PyCharm (Python), RubyMine (Ruby) and Rider (C#), so we upsampled from these languages.
Language Distribution
Next-Edit Autocomplete
While SAFIM improved traditional autocomplete by focusing on syntactically valid completions at frequently changed code locations, many developers asked for suggestions beyond their current cursor position. This led us to next-edit autocomplete.
What is next-edit autocomplete? Instead of only suggesting changes right after the developer’s cursor position, it predicts related changes elsewhere in the file. For example, after adding a new parameter to a function definition, it might suggest using that parameter in the function body. Or after modifying a function signature, it could update the callers automatically.
How do we generate diffs from autoregressive models?
We can rewrite the code around the current cursor position, diff the result, and display that back to the user. To add max_depth to the recursive call above, this looks like:
Input:
self.search_recursive(
node.left,
value,
)
Output:
self.search_recursive(
node.left,
value,
max_depth - 1 if max_depth is not None else None
)Doing this naively will yield performance issues, but as you’ll see later, speculative decoding accelerates this drastically.
We sampled these next-edit diffs from having a larger frontier LLM generate a large number of small related changes on the OSS repositories we scraped.
We trained our autocomplete model with full-parameter supervised fine-tuning via TRL. Though we’ve seen that many others have had success with LoRAs, from our testing, parameter-efficient fine-tuning makes the model struggle even at learning basic pattern matching, such as identifying where the last change has been made.
We trained on a 8xH200 on Modal, as they were the easiest way to get access to H100s/H200s at the time and allowed us to quickly iterate on our training runs.

Deployment
With our training approach established, we turned to the second critical requirement: speed. Having a high-quality model means nothing if developers have to wait for suggestions. This brought us to our deployment and optimization challenges.
We started with prototyping on vLLM on an L40S on an AWS g6e.xlarge (relatively modern GPU that was easy to procure). There were almost no H100s available at this time, and we had no quota on GCP.
Quickstart on vLLM
vLLM is an OSS LLM-inference engine written in Python, and it’s by far the easiest inference engine to set up, since their docker image works out of the box. However, it’s not very optimized as you will see later. The initial benchmark reveals:
| Metric | P50 | P90 |
|---|---|---|
| TTFT | 197.3ms | 340.7ms |
| Decoding | 2988.7ms | 4340.2ms |
| Total | 3338.5ms | 4558.8ms |
As you can see, decoding can take ~3s which is by far the bottleneck with generating next-edit autocompletions.
Speculative Decoding
Our initial vLLM setup revealed that decoding was the primary bottleneck. To address this, we implemented speculative decoding.
Speculative decoding is an inference optimization that accelerates LLMs by predicting multiple tokens at a time rather than one token at a time. The key insight is that most tokens in language (especially programming languages) are highly predictable:
export function useList<T>(initialItems: T[] = []): UseListReturn<T> {
const [items, setItems] = useState<T[]>(initialItems);
if (items.length > 0) █ // <- almost always a {In fact, this is so predictable even a small language model can predict it. So can we get the smaller model to generate the easier tokens and the larger model to generate the harder tokens?
Unfortunately, this approach is lossy and requires a third auxiliary model to determine which model to use. But there’s a better way to do this.
The second insight is that performing a forward pass (i.e. computing the logprobs) over the next 8 tokens can be parallelized on the GPU so that it takes about the same amount of time as inferencing one token. We can use a smaller model (called the draft model) to draft the next n tokens and then have the original model (called the target model) verify the next n tokens - i.e. generate logprobs for each token and keeping all the draft tokens that match the target model’s inference.
Think of it as giving the target model autocomplete. Here’s an animation from Google:
So if the average acceptance rate is , then on average number of accepted tokens being , which is also approximately the speedup without considering the draft model’s overhead. For code, this number ends up being around ~60%, resulting in a ~3.5x speedup!
N-gram Lookup
However, inferencing the draft model is expensive. One clever insight is that code is highly repetitive — the majority of tokens can be copied from context. So the trick (known as n-gram lookup) is to replace the draft model with a “model” that just copies tokens from the prompt. This “model” searches for the longest match of the last k tokens of the prompt that occurs elsewhere in the prompt, then copies the tokens that follow this match.
For example, in this Python script it would search for _recursive(self, node, value), find a match at def _search_recursive(self, node, value): and then copy over the body of _search_recursive(self, node, value) as the draft tokens:
def _search_recursive(self, node, value):
if node is None or node.value == value:
return node
if value < node.value:
return self._search_recursive(node.left, value)
return self._search_recursive(node.right, value)
def delete(self, value):
self.root = self._delete_recursive(self.root, value)
def _delete_recursive(self, node, value):█ // <- user's cursor
if node is None or node.value == value:
return node // <- proposed draftFurther, in the context of next-edit autocomplete, >90% of the tokens will be unchanged when we rewrite the code around the cursor, so it’s even faster.
Turning this on in vLLM, we get a 10x improvement on decoding time and a 5x improvement on total time:
Vanilla vs Speculative Decoding (P50)
Hardware Upgrade
While speculative decoding provided significant improvements, we knew we could push further with better hardware. Around this time we finally got our H100 quota from GCP, and a quick benchmarking reveals a ~3x speedup across both TTFT and decoding time. Turning on vLLM’s FP8 dynamic quantization and torch compile yields another ~20% boost:
L40S, H100, and H100 + Optimizations (P50)
TensorRT-LLM
Even with H100s, we weren’t satisfied with the performance. This led us to try TensorRT-LLM. TensorRT-LLM (TRT-LLM) is a more performant LLM inference engine built by Nvidia based on TensorRT in C++. It’s a much faster inference engine but it being in C++ and from Nvidia makes it significantly harder to set up. Further, at the time, n-gram speculative decoding was not supported. However, we decided it was worth the effort to fork it and add n-gram support ourselves.
The majority of the work was getting TRT-LLM to even build, as the core executor and scheduler is written in C++. However, once it was building successfully, it was relatively straightforward to add and test n-gram speculative decoding.
On the algorithm side, others have built suffix automata or KMP for doing n-gram search faster, but we’ve found naive linear search to be sufficient. We approximate from our testing that even if we hit the worst case for every one of the 32k tokens, the upper bound for the overhead would be ~5ms.
Without quantization TRT-LLM is actually slower than vLLM, but with FP8 E4M3 quantization it achieves significant improvements:
vLLM vs TensorRT-LLM Latency (P50)
We can squeeze even more performance out using FP8 KV Cache, but we struggled to get this to work. We found that the root cause appears to be related to our base model having biased attention. This requires asymmetric quantization to cache activations, which is currently not well-supported by ModelOpt, the model optimization framework used by TensorRT-LLM.
We also implemented another trick: when we know that the model has generated enough changes that it’s ready to show to the user, we can return the result early and cancel the rest of the stream. With this optimization we get:
TRT-LLM FP8 vs FP8 + Early Cancellation (P50)
All these benchmarks are computed with a cold KV cache. With a warm KV cache the typical request takes around 10ms of TTFT and 50ms of decoding, which is approaching the theoretical limits of how fast we can display suggestions to the user since UI rendering can take ~10ms and network latency is ~30ms.
In summary, here’s a breakdown of all the optimizations:
Next-Edit Autocomplete Latency (P50)
With response times now faster than human typing speed, we are able to generate suggestions for every keystroke, feeling significantly more responsive than other autocompletions available in JetBrains IDEs.
Try us out
We’ve built an autocomplete system that delivers both high-quality suggestions with sub-100ms response times. Here’s an example of a refactor that our system excels at, running at production speeds. This is not sped up:
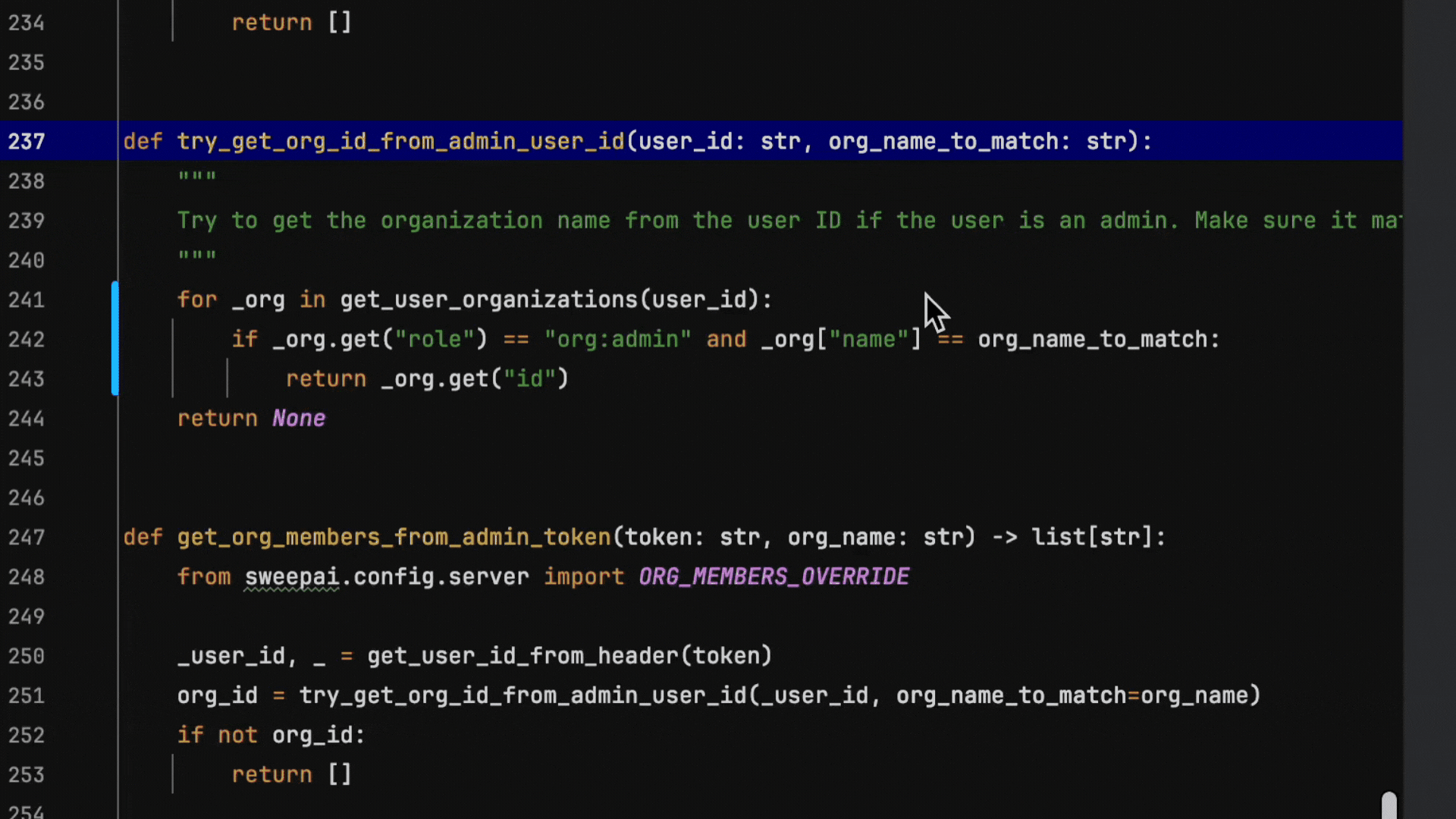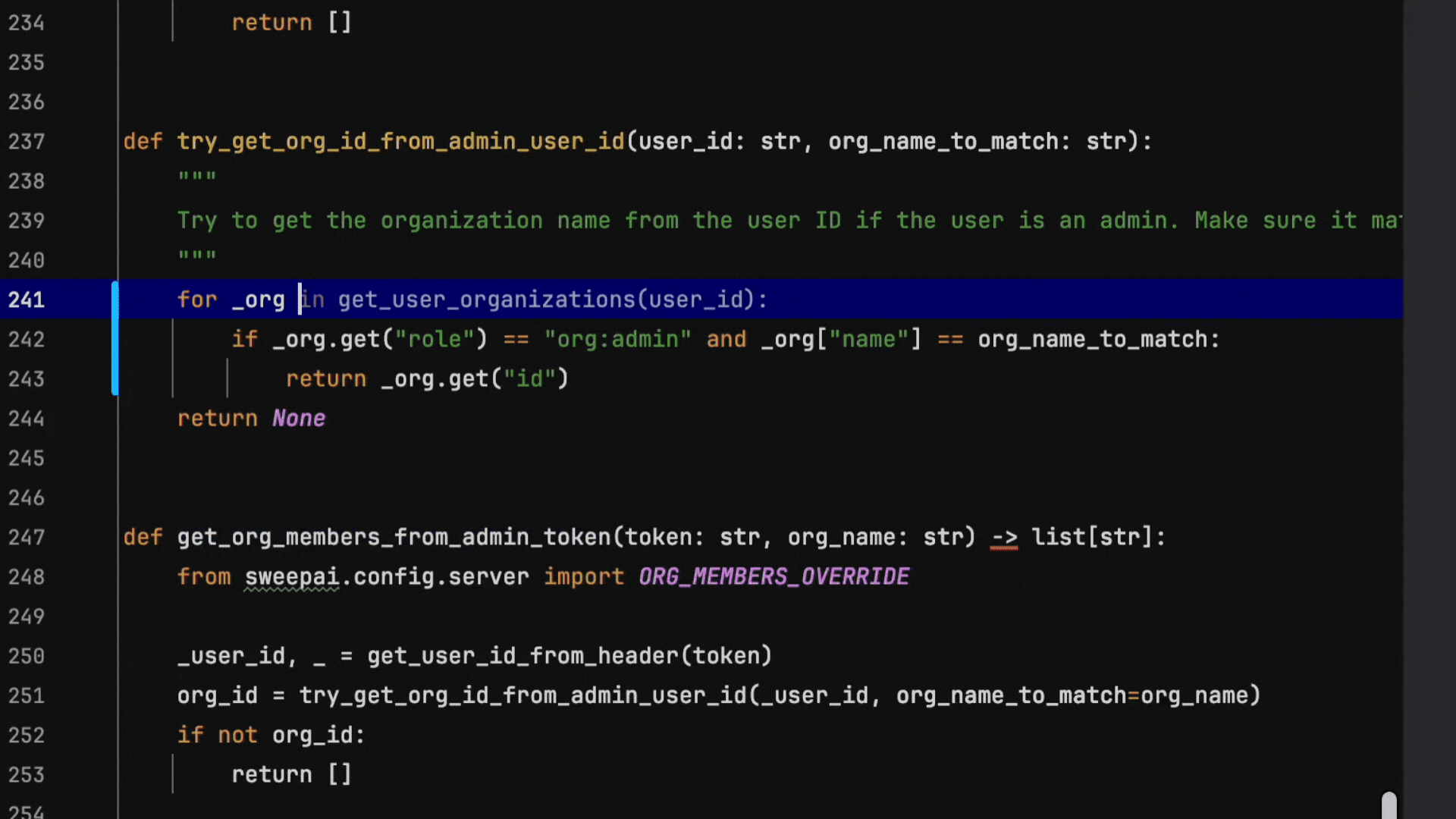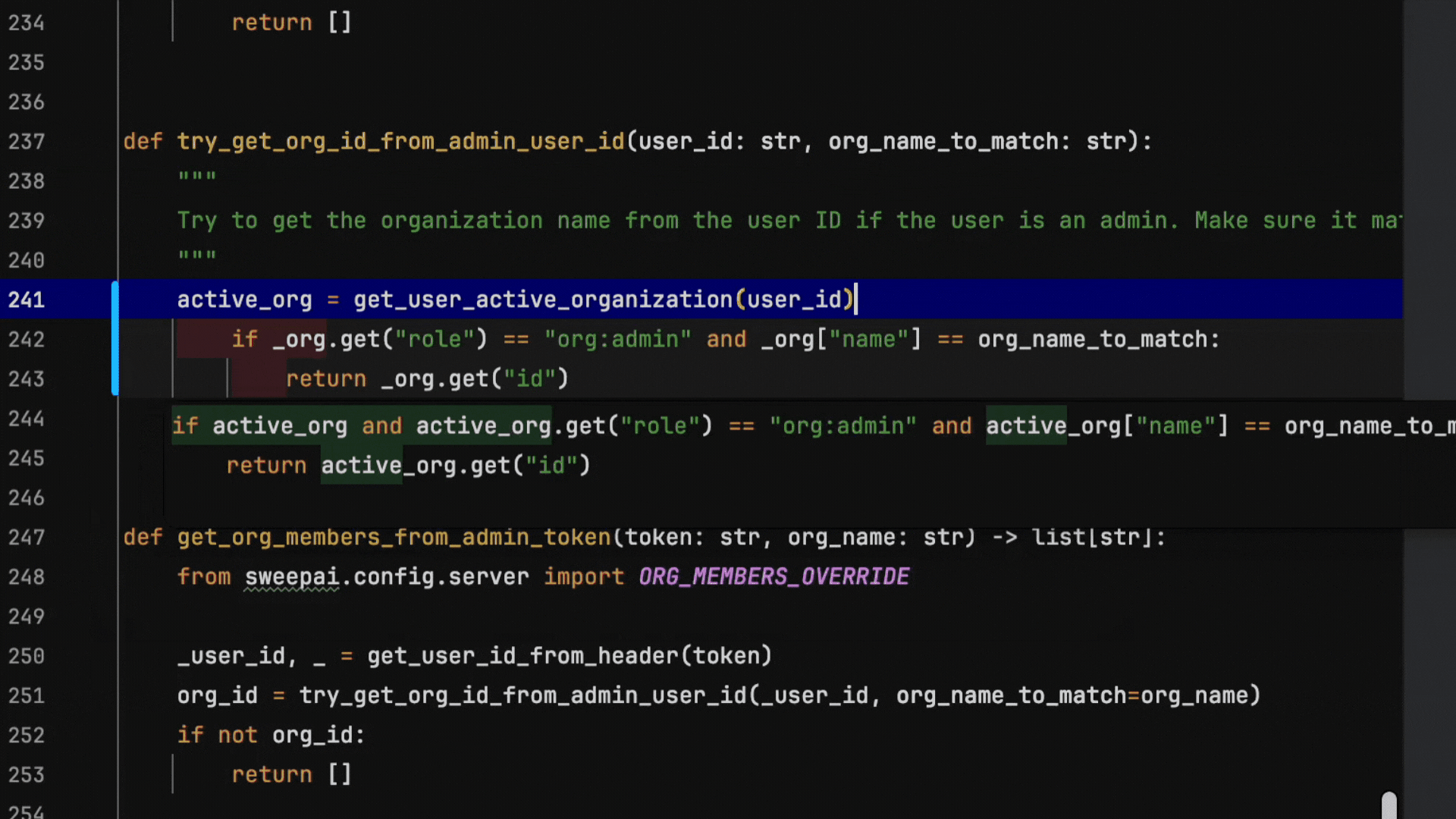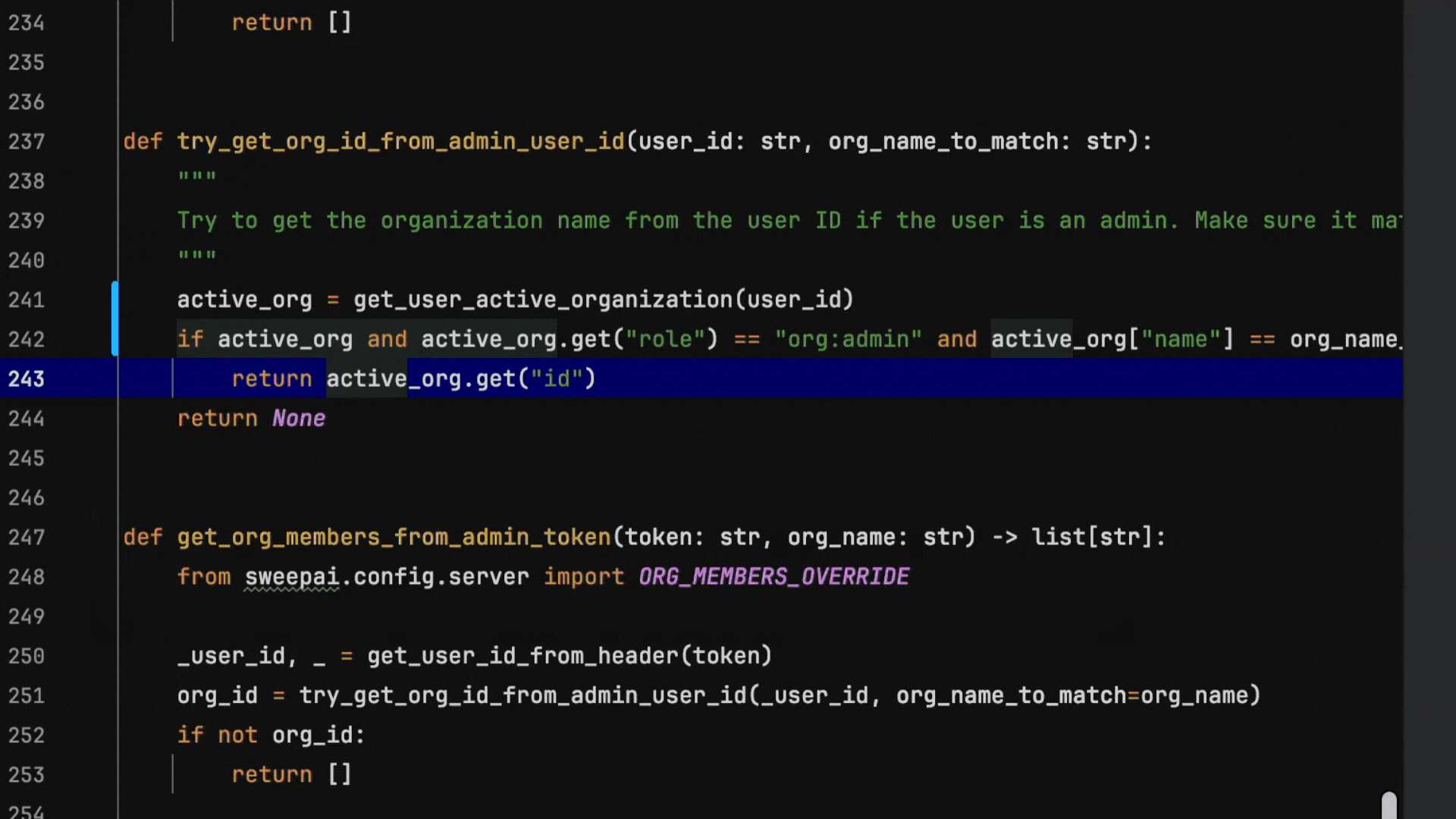
Notice at every keystroke, our autocomplete is fast enough to make a suggestion and smart enough to understand intent.
If you use JetBrains IDEs, we’d love for you to try out Sweep and let us know what you think.